
El atributo HTML autocompletar permite a los desarrolladores web especificar si el agente de usuario tiene permiso para proporcionar asistencia automatizada en la cumplimentación de los valores de un campo de formulario, así como guiar al navegador en cuanto al tipo de información que se espera en el campo. Está disponible en elementos <input> que […]
Recursos


D3.js (Data-Driven Documents) es una biblioteca JS para visualizar datos en formas gráficas dinámicas. Se trata de una herramienta para la visualización de datos bajo estandards W3C haciendo uso de HTML5, SVG, JavaScript y CSS3. A diferencia de muchas otras bibliotecas, D3 permite un gran control sobre el resultado visual final. D3 permite enlazar datos […]
Buscadores, Optimización, Recursos, SEO
Google SERP Tool – Previsualización de resultados de búsqueda en Google
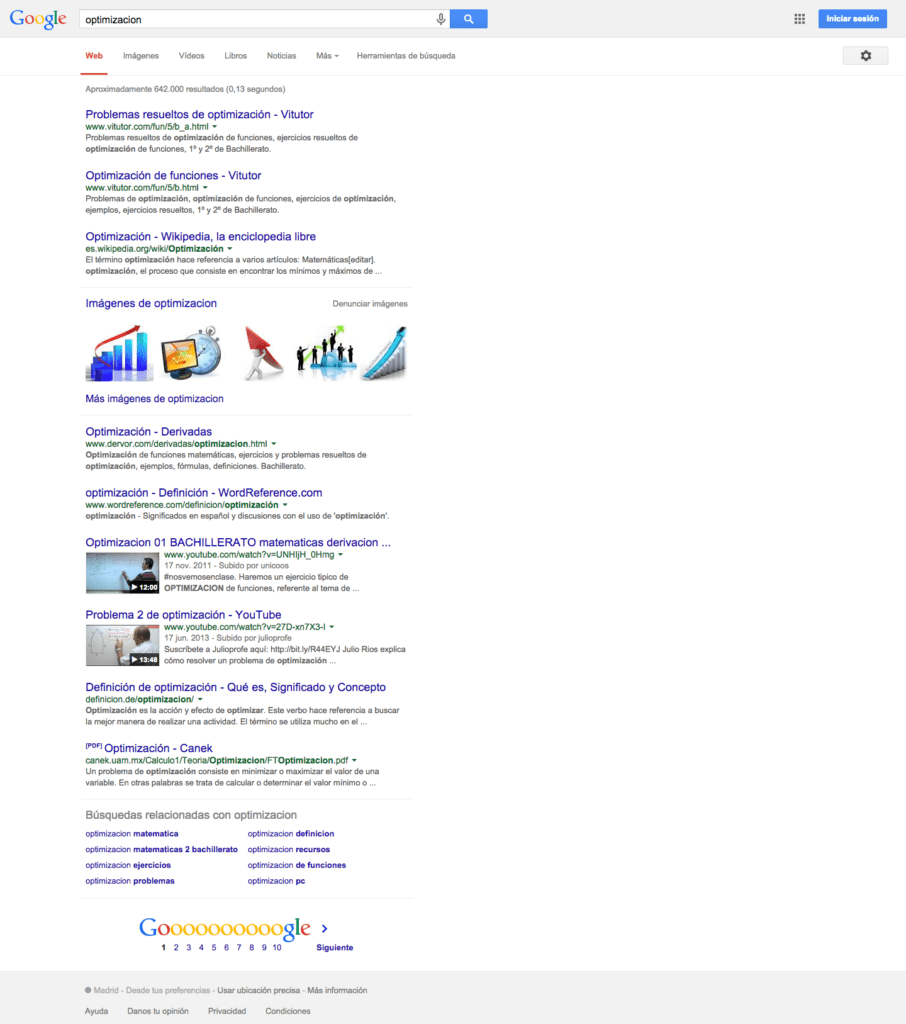
Resultados de búsqueda en Google Un resultado típico Título: la primera línea de cualquier resultado de búsqueda es el título de la página web. Haz clic en el título para acceder a esa página web. URL: la dirección web de la página web del resultado aparece de color verde. Fragmento (Descripción): se trata de una […]
Buscadores, Google, Optimización, Recursos, SEO, Tutoriales
Consejos prácticos para salir de la penalización Penguin

En MaisMedia hemos recibido a Penguin como una actualización más; y es que con el correr de los días, se le va perdiendo el miedo al nuevo monstruito de google, y es que si nos ponemos analizar las cosas ya con la cabeza fría, nos daremos cuenta que Google Penguin y Panda trabajan básicamente en […]